In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure whose internal nodes each store a key greater than all the keys in the node’s left subtree and less than those in its right subtree. A binary tree is a type of data structure for storing data such as numbers in an organized way. Binary search trees allow binary search for fast lookup, addition and removal of data items, and can be used to implement dynamic sets and lookup tables. The order of nodes in a BST means that each comparison skips about half of the remaining tree, so the whole lookup takes time proportional to the binary logarithm of the number of items stored in the tree. This is much better than the linear time required to find items by key in an (unsorted) array, but slower than the corresponding operations on hash tables. Several variants of the binary search tree have been studied.
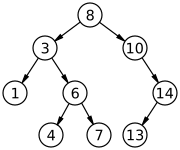
Definition
A binary search tree is a rooted binary tree, whose internal nodes each store a key (and optionally, an associated value), and each has two distinguished sub-trees, commonly denoted left and right. The tree additionally satisfies the binary search property: the key in each node is greater than or equal to any key stored in the left sub-tree, and less than or equal to any key stored in the right sub-tree.[1]: 287 The leaves (final nodes) of the tree contain no key and have no structure to distinguish them from one another. The shape of the binary search tree depends entirely on the order of insertions and deletions and can become degenerate.
Often, the information represented by each node is a record rather than a single data element. However, for sequencing purposes, nodes are compared according to their keys rather than any part of their associated records. The major advantage of binary search trees over other data structures is that the related sorting algorithms and search algorithms such as inorder traversal can be very efficient.[note 1]
Binary search trees are a fundamental data structure used to construct more abstract data structures such as sets, multisets, and associative arrays. There has been a lot of research to prevent degeneration of the tree resulting in worst case time complexity of O(n) (for details see section Types).
Order relation
Binary search requires an order relation by which every element (item) can be compared with every other element in the sense of a total preorder. The part of the element which effectively takes place in the comparison is called its key. Whether duplicates, i. e. different elements with the same key, shall be allowed in the tree or not, does not depend on the order relation, but on the underlying set, in other words: on the application only. For a search function supporting and handling duplicates in a tree, see section Searching with duplicates allowed.
In the context of binary search trees, a total preorder is realized most flexibly by means of a three-way comparison subroutine.
Operations
Binary search trees support three main operations: lookup (checking whether a key is present), insertion, and deletion of an element. The latter two possibly change the structural arrangement of the nodes in the tree, whereas the first one is a navigating and read-only operation. Other read-only operations are traversal, verification, etc.
Searching
Searching in a binary search tree for a specific key can be programmed recursively or iteratively.
We begin by examining the root node. If the tree is 
Recursive search
The following pseudocode implements the BST search procedure through recursion.[1]: 290
Iterative search
The recursive version of the search can be "unrolled" into a while loop. On most machines, the iterative version is found to be more efficient.[1]: 291
Since the search may proceed till some leaf node, the running time complexity of BST search is 




Maximum and minimum
Operations such as finding a node in a BST whose key is the maximum or minimum are critical in certain operations, such as determining the successor and predecessor of nodes. Following is the pseudocode for the operations.[1]: 291–292
Successor and predecessor
For certain operations, given a node 
Traversal
A BST can be traversed through three basic algorithms: inorder, preorder, and postorder tree walk.[1]: 287
- Inorder tree walk: Nodes from the left subtree get visited first, followed by the root node and right subtree.
- Preorder tree walk: The root node gets visited first, followed by left and right subtrees.
- Postorder tree walk: Nodes from the left subtree get visited first, followed by the right subtree, and finally the root.
Following is a recursive implementation of the tree walks.[1]: 287–289
Height
Height of the binary search tree is defined as the maximum of the heights of left subtree and right subtree incremented by a factor of 1. Following is a recursive procedure for calculating the height of the BST given a root
Insertion
Operations such as insertion and deletion cause the BST representation to change dynamically. The data structure must be modified in such a way that the properties of BST continue to hold. New nodes are inserted as leaf nodes in the BST.[1]: 294–295 Following is an iterative implementation of the insertion operation.[1]: 294
The procedure maintains a "trailing pointer" y as a parent of x. After initialization on line 2, the while loop along the lines 4-11 causes the pointers to be updated. If y is nil, the BST is empty, thus z is inserted as the root node of the binary search tree T, if it isn't nil, we compare the keys on the lines 15-19 and insert the node accordingly.[1]: 295
Deletion

Deletion of a node 

- If
- If
- If
and have it take
- If
- If
- If
Following is a pseudocode for the deletion operation in a binary search tree.[1]: 296-298
The 



Examples of applications
Sort
A binary search tree can be used in sorting algorithm implementation. The process involves inserting all the elements which are to be sorted and performing inorder traversal. This method is similar to that of quicksort where each node corresponds to a partitioning item that subdivides its descendants into smaller keys and larger keys.[3]
Priority queue operations
Binary search trees are used in implementing priority queues, using the element or node's key as priorities. Adding new elements to the queue follows the regular BST 
- If it's an ascending order priority queue, removal of an element with the lowest priority is done through leftward traversal of the BST i.e.
.
- On the other hand, if it's a descending order priority queue, removal of an element with the highest priority is done through rightward traversal of the BST i.e.
.
Types
There are many types of binary search trees. AVL trees and red–black trees are both forms of self-balancing binary search trees. A splay tree is a binary search tree that automatically moves frequently accessed elements nearer to the root. In a treap (tree heap), each node also holds a (randomly chosen) priority and the parent node has higher priority than its children.
Tango trees is an online binary search tree which is optimized for fast searches and achieves an 
T-tree is a balanced binary search tree optimized to reduce storage space overhead which are used for in-memory databases.[6]
A degenerate tree is a binary search tree which contains 
Performance comparisons
In regards to performance characteristics of binary search trees, a study shows that Treaps perform better on average case, while red–black tree was found to have the smallest number of performance variations.[8]
Optimal binary search trees
Optimal binary search tree is a theoretical computer science problem which deals with constructing an "optimal" binary search trees that enables smallest possible search time for a given sequence of accesses.[9]: 449–450 The computational cost required to maintain an "optimal" search tree can be justified if search is more dominant activity in the tree than insertion or deletion.[10][9]: 449
Threaded binary trees
A threaded binary search tree is an accessorial version of a binary tree whose 
- One-way threading: The left or right pointer field of the nodes, holds a reference to the inorder predecessor or inorder successor, but not both.
- Two-way threading: The left and right pointer fields hold the references to the inorder predecessor and inorder successor respectively.
| This article uses material from the Wikipedia article Metasyntactic variable, which is released under the Creative Commons Attribution-ShareAlike 3.0 Unported License. |